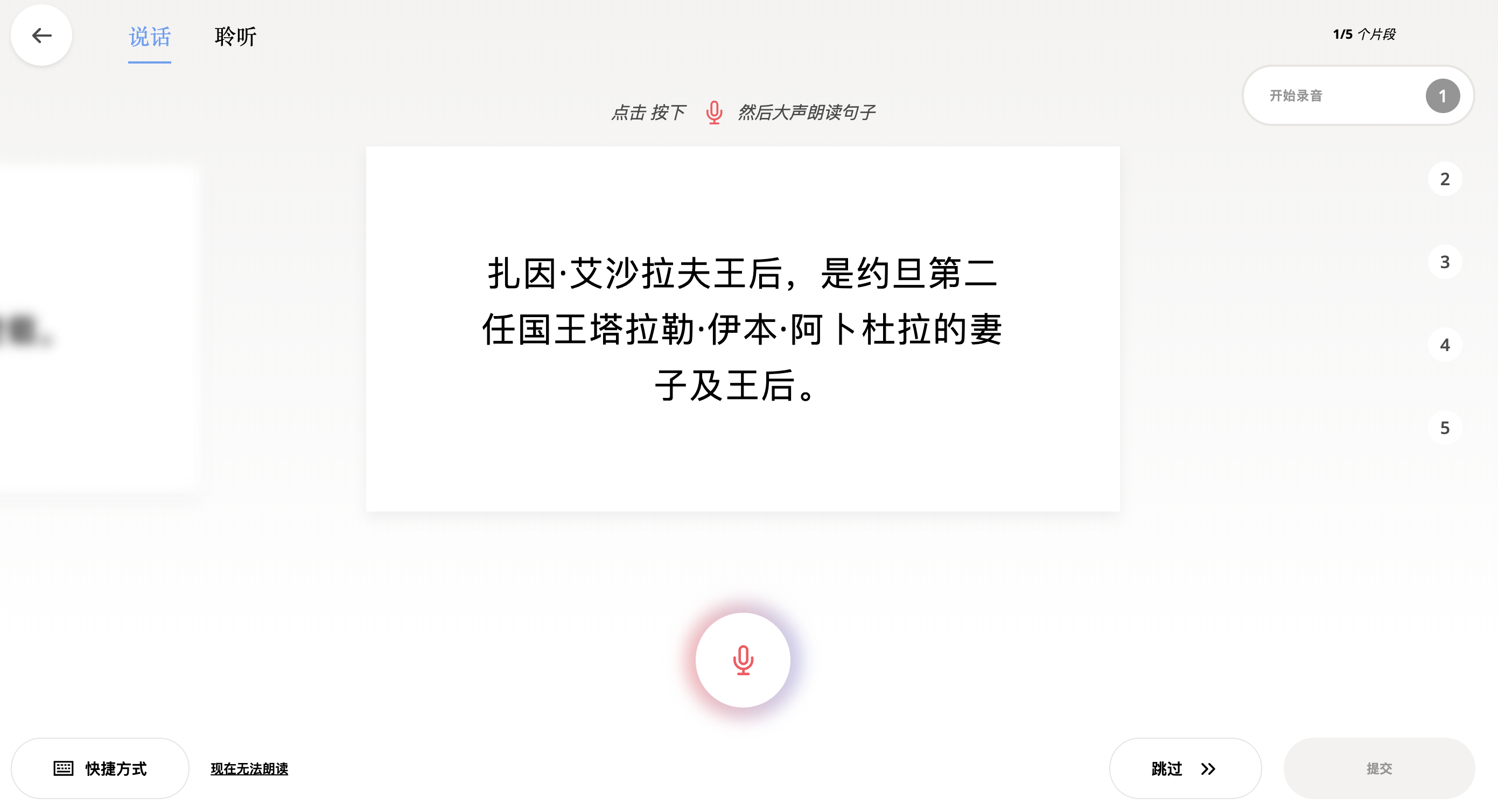
语音是自然的、有人性的。这也是为什么我们希望为机器建立可用的语音技术。但要创造一个语音系统,开发者需要大量的语音数据。
大部分由大公司持有的数据,并未开放给公众使用。我们认为这会扼杀创新,因而推出了Common Voice项目,让语音识别技术的大门对每个人开放而无障碍。
现在,您可以贡献出您的声音,帮助我们建立一个开源的语音数据库,任何人都可以使用它来为设备和网络制作创新的应用程序。 只要朗读一段文字,即可帮助机器了解人们如何说话。您也可以复查其他贡献者的工作以提高质量。就这么简单!
前段时间在公众号上看到了又有一个语音的数据集公开了,后来某一天有意无意的就去查了下这个数据集,点开了Common Voice的官网,就看到了上面那一段话。一直都会被这种真正为了整个世界进步的精神所感染。
在之前公司工作的时候一个逃不掉的问题就是数据了,总是会因为没有开源的数据或者数据量太少而捉襟见肘,而大公司们就可以利用现有的资源去获得海量的数据。所以一开始看到Common Voice的官网就格外的激动,不过那个时候汉语(中国大陆)还没有上线,还在准备当中,于是就先去验证了几个汉语(台湾)的片段,也大概搞懂了它收集数据的方式。
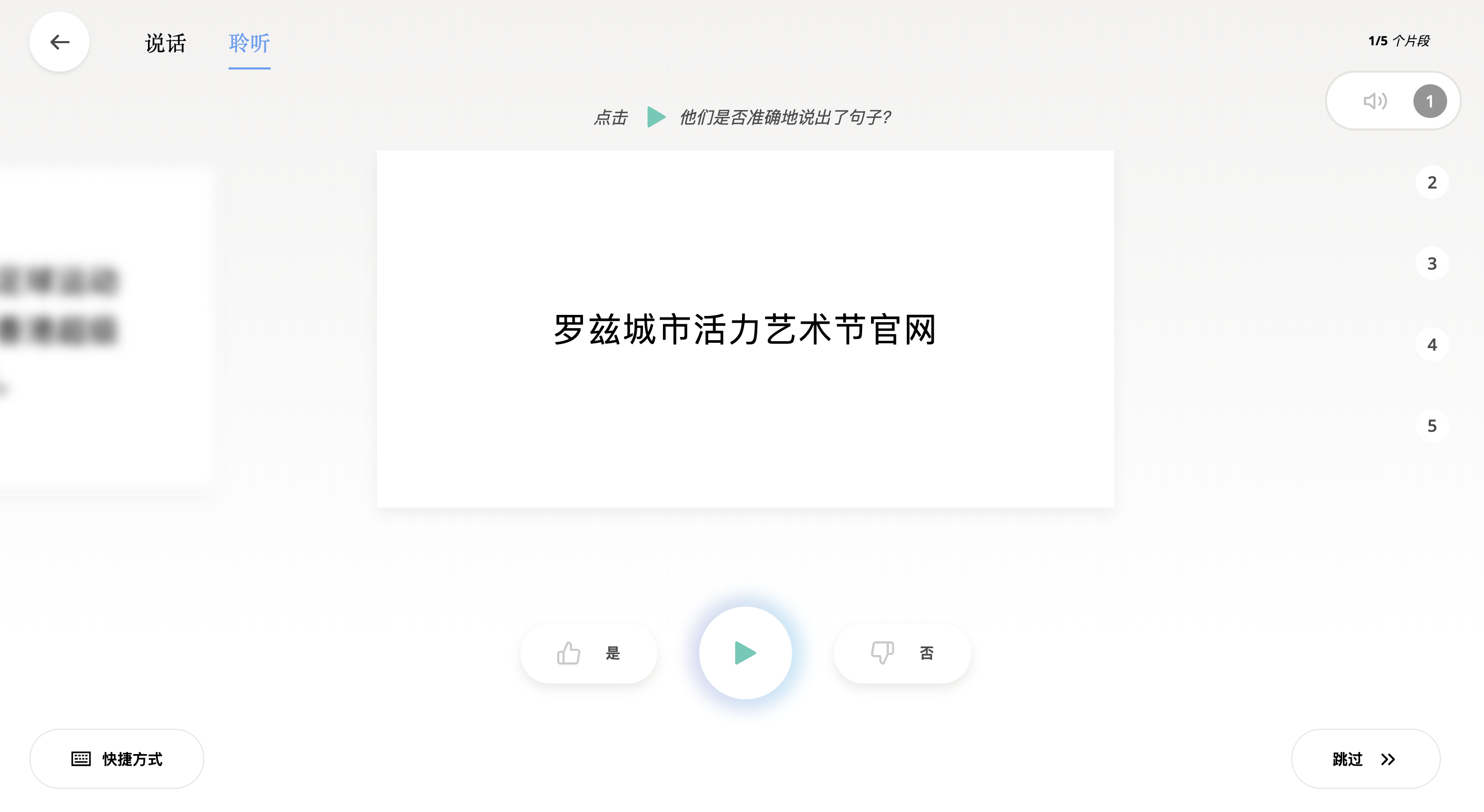
每个人都可以贡献自己的录音,朗读屏幕上的句子;也可以去验证别人读的句子,听别人读的和屏幕上的文本是否一致,如果3个人有2个人认为是对的就可以收录进数据集当中了,虽然感觉验证的次数可能稍微少了点,不过这也是为数不多不用专用的数据标记人员来制作数据集的办法了吧。
目前Common Voice已经上线了23种语言,汉语(中国大陆)也终于上线了,我也马上去录制了几段语音🎙,快来和我一起成为一个「数据标记员」吧~
最后再吐槽下Common Voice选的文本也太拗口了吧,就像下面这段话,都要读好几遍才能读得通顺。而且感觉选的文本都有点太过于书面化了,还有不少的文言文🤦♂️,不过瑕不掩瑜吧。